A Complete Guide to Using AI in Problem Solving

Every day we solve dozens of problems without a second thought. During a road trip, you do not start thinking about weather and the distance — your brain immediately computes to find the fastest route and schedules rest-stops. For example, if a road closes down, you quickly adjust, and find another way.
We, humans, have this cognitive flexibility in our nature. The machine, rather, must divide every step into something that is logical and mathematical.
Internally, artificial intelligence and problem solving is the study of how to teach machines to overcome obstacles and discover best paths to a goal. Humans, meanwhile, can often make intuitive leaps borne not just of experience but also sheer random luck; computer systems must devise structured search spaces dig into heuristics and share their reasoning algorithmically.
One of the earliest beliefs about computer science was that artificial intelligence, or AI, and problem solving were virtually indistinguishable. The aim was the creation of a “General Problem Solver”, one computer program capable of using the same most fundamental rules of reasoning to solve any logical puzzle, from chess to symbolic integration.
Although that dream turned out to be much more complicated than pioneer researchers had ever imagined, the techniques borne from that pursuit became the building blocks for all of the intelligent software we use today.
Search Space: A Challenge from the Machines Perspective
If we want to really understand where artificial intelligence meets problem solving, we need to look at how a machine thinks of a challenge. A computer does not understand a cluttered room simply and “know” how to clean one. The problem must be more formally defined from a framework called state-space.
Mathematically, a state-space is actually the map to all situations the machine may eventuate into. It is made up of few important components:
- Initial State: This represents the initial state. This is what the board looks like before anyone makes a move for an AI playing chess.
- Actions; The valid moves or choices that the AI can take at each point in time.
- Transition: What do we actually do when something happens. For example if the AI moves a pawn forward, then the transition model updates the state of chess board after moving that piece from its original position.
The Goal Test: This is the fact or condition if the problem has been solved now. Has the opposing king been checkmated? Did the delivery truck make deliveries?
- The Path Cost : It finds out the resources, used to solve your problem e.g. in terms of Time or Distance or Power from computer. The objective of the AI is usually retrieving a path with the least cost.
Translating a real-world scenario into those specific variables allows an ai to cast any challenge as a gigantic puzzle or maze that it needs to escape from, logically.
Generalization from Toy Problems to Harder Troubles
Scientists in AI research sometimes make a distinction between “toy problems” and “real-world problems”. A toy problem typically refers to a simplified, sanitized scenario for testing new algorithms. Some classic examples are an 8-puzzle (small sliding tiles to rearrange numbered them in order) or the famous “Tower of Hanoi” They are constrained by hard-wired rules, minimal state space, and the lack of external noise.
In contrast, real-world problems are messy and chaotic. Autonomous cars or global supply chain management; both of them require designing algorithms for openended environments where rules can change instantaneously, information is incomplete and the search space is practically infinite.
The shift from simple puzzles to complex environments represented an enormous advance in AI and solving strategies. Modern systems are no longer constrained to find that “perfect” mathematical solution but instead search for a “good enough” solution within a time sufficient to solve the problem.
Uninformed search algorithms (classic way)
Because a state-space can be huge, an AI has to rely on a search algorithm in order to make decisions. The simplest type among these algorithms is called “uninformed search” (or also blind search). These algorithms have no outside hints or signs of how far they are from the target, but only exploration in some semi-systematic pre-programmed way through state-space.
Two of the most popular uninformed search strategies are:
Breadth-First Search (BFS)
The BFS learn about of state-space countries flag by means of layer. It examines every move that can be made from the initial configuration, then all moves possible from those configurations and so forth.
- Pros: Complete, if one exists shortest path to goal ·
- Cons: you must store in computer memory every single state it has visited on all layers, so it adds up to a massive amount of computer memory.
Depth-First Search (DFS)
DFS takes the opposite approach. It picks one path and goes as far down the road as it can, backtracking when necessary to pick a different road.
- Benefits: BFS takes very less memory as compared to GFS.
- Cons: Does not always guarantee a shortest path & can get stuck in an infinite loop when the state-space is under-constrained.
‘In the end, it is the choice of search algorithm which determines how artificial intelligence and problem solving systems perform in practice.’ Blind search works good for basic puzzles, but to solve any complex/real-world problems you need a much smarter informed approach.
Search : Informed Search + Heuristics
Uninformed search algorithms: this is literally like searching a book in a huge library by reading every single title of every single book to know which one you are looking for, from the entrance. Not that you wont find the book, it is just a very long winded process.
Computers, typically need a compass to tackle complex, large scale problems. That is where informed search—typically via “heuristics”—enters the picture.
In simple words, A heuristic is just a guideline of thumb, an educated guess or shortcut. While it does not promise a mathematically perfect solution every time, it drastically speeds up finding one that is very good.
Human-like intuition allowed AI and problem solving methodologies to scale massively. Rather than analysis of all potential routes, the system uses heuristics to prioritize routes that appear more promising.
Say you are building a GPS navigation system to get from city A → City B; a heuristic could be the —line-of-sight distance— (if one exists: aka as the bird travels) from any intersection to City B. Better by far drive toward intersections that physically come closer to your target than pursue roads that take you away!
The well-known A* search algorithm
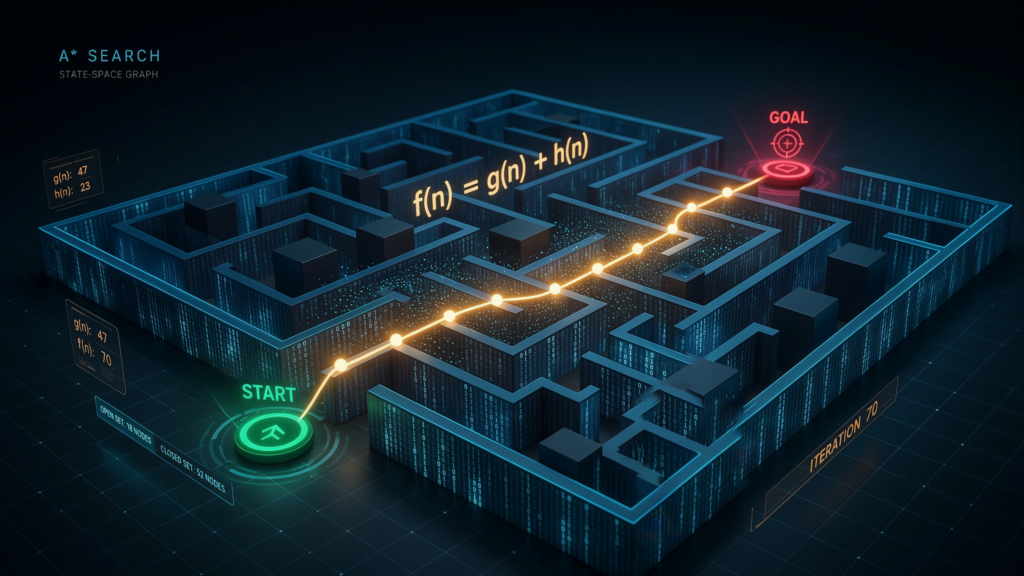
A* (A-star) algorithm, developed in 1968 is the state-of-the-art of heuristic based search. A* search is considered one of the most successful pathfinding algorithms in computer science because if it balances both sides of the coin: past vs future.
A* works by assessing paths with an easy maths:
f(n) = g(n) + h(n)
- g(n): the cost (time, distance, or effort) from start to point n. It brings the algorithm back to a reality check.
- h(n) : This heuristic is an estimate of the cost to get from n to the goal. Certain portions of the data alone will guide the algorithm in the right direction.
- f(n): The total estimated cost of the cheapest solution through the current position.
This clean formula is precisely why A* is one of the most popular algorithms used in modern artificial intelligence and problem solving applications, from GPS navigation to video game pathfinding. It allows video game characters to traverse detailed, wall-dense virtual worlds in real time without bogging down the computer’s processor.
Game playing and Decision Making are adversarial search areas in AI.
Artificial intelligence and problem-solving step up to an entirely different level when you get into competitive situations. In problems such as Tic-Tac-Toe, Chess, or Go the AI has to compete with an opponent who is actively trying to beat it — it doesn’t just have to find a path to a goal.
Computer scientists apply adversarial search algorithms in these competitive settings to mimic moves of the rival and make strategic decisions.
1: THE MINIMAX ALGORITHM AND ALPHA-BETA PRUNING
Although it is the backbone for modern-day game-playing AI very few today actually use vanilla Minimax (more on this later). Minimax assumes that both players play perfectly. The AI (aka “Maximizer”) wants to pick the move that gives it as many points as it can and the opponent (the “Minimizer”) always chooses whichever move reduces the most its score.
Minimax goes many moves ahead, creating an enormous “game tree” of future board states. Monte Carlo trees begin at the bottom of the tree (the final simulated outcomes) and works upwards, assuming that at every turn, the opponent will make the smartest counter-move possible.
But this means you can’t search the entire tree for complex games like Chess as it becomes impractical. The potential positions of the board are more than the atoms in the observable universe. Researchers came up with Alpha-Beta Pruning to tackles this.
Alpha-Beta pruning serves as a great mental filter and shows us why smart AI & problem solving are not just about searching everywhere but knowing where NOT to search. If the algorithm finds a part of the tree that is worse than an option it already found, it prunes that part of the tree as well. It halts its computation down that path, conserving significant amounts of CPU processing power for more likely moves.
Constraint Satisfaction Problems (CSPs)
Most of the real-time challenges does not have single direct way navigating to a goal. Instead, you have to search for a state where all of these complicated rules are satisfied. They are referred to as Constraint Satisfaction Problems (CSPs).
CSPs might take the form of scheduling classes in a high school, assigning radio frequencies to cellular towers, or completing a Sudoku. In a CSP, you have:
- Variables: What we have to decide (e.g. class times)
- Domains: the set of possible values those variables can take (e.g. 9:00 AM, 10:00 AM … etc.)
- Constraints: What are the rules that you cannot break (for example, a teacher cannot teach two classes at the same time).
Artificial Intelligence and Problem Solving engines can immediately reject millions of impossible combinations by considering scheduling or allocation tasks as CSPs. The system does not hope for a miracle to guess randomly, it makes use of heuristics as the “Minimum Remaining Values” taking care to fill in restricted boxes first in an attempt to solve enormous and logistically complex problems under seconds.
The Machine Learning Paradigm Shift

The standard way to program a computer has been for generations: if X, do Y; if Z, do W, a set of very explicit instructions.
As another example, picture trying to write out a rule-based approach for how to recognise a handwritten digit or translate spoken French. No human can write down all the variations, nuances, and exceptions.
The weaknesses of true manual heuristics in generalization made machine learning the best option, paving a new path for artificial intelligence and problem-solving capabilities as problems became more abstract.
In machine learning, instead of humans hard coding the rules on how to solve a problem, we use algorithms that take massive amounts of data as input. It trains on the patterns found in this data and basically writes its own internal rules.
So with these new paradigms, instead of telling the computer how to solve a problem; we show it what a solved problem looks like, and let it navigate its own journey there.
Reinforcement Learning: Learn by Doing
Reinforcement Learning (RL) is one of the most captivating areas in contemporary machine learning. In contrast to supervised learning, where an algorithm is emphasized by a pre-labeled dataset from human instructor, this method of reinforcement learning is totally self-sufficient upon trial, error and feedback.
A reinforcement learning system consists of an agent( the AI) that happens to be placed within a environment (i.e. a maze, in a flight simulator, or in some grid like pixelated region of space via computer program). The agent is able to “take actions” on the environment. With each action, the agent transitions to a new state.
We create a “reward system” to steer the agent towards the goal. If it takes an action to get closer to the goal, it gets a reward (a positive reward). It is then punished (penalized) when it makes an error. Through their learning processes, the agent is trained on millions of repetitions and learns a policy—a string/strategy of how to select an action at that state for maximum total long-term reward.
That is why trial and error method is a usual characteristic of modern artificial intelligence and problem solving in changing, uncertain environments. It enables systems to explore highly imaginative, non-obvious solutions to difficult problems that human designers never would have dreamed of programming.
Related Reading: What is Deep Learning — Understanding Neural Networks as a simple example of using DL, which concept in RL are driven by neural networks [H3]
Basic reinforcement learning is more successful in small structured environments, but fails to generalise to complex problems such as those with millions of possible states. To go beyond this restriction, researchers coupled reinforcement learning with deep neural networks.
It was possible now to make sense out of raw visual data such as pixels on a screen, and with the addition of deep neural networks, artificial intelligence and problem solving systems could understand it.
Rather than rely on a clean set of inputs, the obs pon new capsule provides its own confirmation list i.e., instead of feeding x-a long pre-packaged list of variables that an RL agent can examine all possible angles from before deciding how to proceed, your network just has say in n frames depending on the model type) each with x dimensions ie video feed camera setup or video game screen within this window. The raw visual input is processed into high level features by a deep neural network, which acts as the “eyes” of the agent, and these features are fed to a reinforcement learning algorithm that makes strategic decisions.
Alpha-Go: The ultimate Problem Solving Use case
Deep Reinforcement Learning was taken to the extreme with AlphaGo (2016 by DeepMind). For a time the ancient Chinese board game Go was seen as the last great challenge of AI.
Go is more complex than chess, and has an average of 250 valid moves per turn compared to Chess’ relatively tame branching factor. Conventional search algorithms like Minimax with Alpha-Beta pruning didn’t have a fighting chance; it was mathematically too difficult to evaluate the strength of a Go board configuration.
DeepMind cracked this enormous problem using a combination of more traditional Monte Carlo Tree Search (MCTS) alongside two deep neural networks:
- The Policy Network: It is trained on millions of human professional moves and predicts which moves are most likely to be good, thus reducing the search space.
- The Value network: It looks at a board position and approximates the probability of winning from that position without searching to the end of the game.
2016 would be the year of a landmark win for AlphaGo, which rewrote the book on AI and problem solving paradigms altogether.
AlphaGo defeated the world champion Go player Lee Sedol by learning to play millions of games against itself, devising strategies that humans had never found after thousands of years playing.
Modern Problem Solving and Code Completion with Large Language Models

Generative AI and Large Language Models (LLMs, like GPT-4), Gemini+Oort or Claude completely changed the rules of computational reasoning once again. These modern models process and generate human language rather than relying on binary trees or maths equations, as older more stiff systems do.
The introduction of generative models signals an unexpected new era in AI and problem solving: this time computers are reasoning in a language we can understand as opposed to raw math.
Through machine-learning methods on petabytes of text, LLMs can recognize relationships between concepts, write code, academic papers and good old logic puzzles.
An important technique that has been developed to improve this ability is Chain-of-Thought (CoT) Prompting. When an LLM is asked to “think step-by-step,” it decomposes a complicated problem into smaller logical steps, one after the other, leading to an answer.
This process resembles human cognitive reasoning very closely. Instead of just coming to a conclusion, the AI states its assumptions and analyzes concerning the midpoints of the problem and modifies its course which means it has an extremely better success rate in resolving math, coding, and logical problems.
Limitations: Filling the “Reasoning Gap”
Even with modern models well-versed in conversation practices, they do not yet perfect the avatars of problem-solver. Cognitive scientists know it as the reasoning gap.
Since LLMs are deep learning models for predictive text generation, they do not have an accurate and grounded mental map of the world. They rely on statistics of appearance to predict each subsequent most likely word, but not because they understand laws of motion or absolute realities.
There are several ways this limitation manifests:
- Hallucinations: An AI will generate a completely incorrect fact, historical event or mathematical theorem, to simply flow with what needs to be said in the sentence.
- Brittle Logic: An LLM can solve a complex math problem perfectly, but change one non-essential word in the input text and you might receive an answer that makes no sense at all because it is simply repeating learned patterns of text rather than understanding abstract ways to derive the solutions.
- No Common Sense: An AI system does not know that it is impossible to put a bowling ball in a teacup like a human would, unless trained directly on those permutations of information.
These errors underscore the limitations of current architectures for artificial intelligence and problem solving: fluent speech alone does not indicate logical correctness. Researchers are searching for “neuro-symbolic” architectures that marry the raw statistical strength of LLMs with the unbreakable logic of classic search algorithms.
Collaborative Intelligence: Bringing out the Best of AI + Humans
In the years to come, it is clear that the best way to tackle our planet’s hardest problems—like climate modelling, drug discovery and macroeconomic planning—is not with machines alone. Rather, the emphasis is moving towards what is described as collaborative intelligence — coined as the “Centaur” or “Cyborg” model of solution.
It is a system in which humans and AI collaborate, ceding labor to those tasks that align best with their unique capabilities.
- Where AI Excels: Identifying hidden correlations between billions of data points within minutes, running thousands of potential chemical formulas through simulations and crunching tedious calculations.
3 · What Humans Do Best: Identifying the ultimate purpose, exercising ethical & moral judgments, calling subtle contextual distinctions and rendering decisive, high-stakes decisions against emotional and social realities.
Ultimately, the art of artificial intelligence and problem solving will not be to take humans out of the equation but rather to work alongside us. The heavy computational lifting is done by smart algorithms—and we humans can focus on creative thinking, empathy and strategy (human areas), and new horizons are open for innovation!
Frequently Asked Questions (FAQ)
Compare & contrast: Wikipage 2-1; Heuristic Search vs. Machine Learning in Artifical Intelligence and Problem Solving
Heuristic search operates on rules that humans have programmed into machine code beforehand (like Straight-Line Distance in pathfinding) that takes a goal and manipulates an algorithm into getting there. Machine learning, in contrast, lets the computer analyze huge datasets and learn its own internal rules and sequence to use to solve a problem without being told how.
We have no other option because any AI agent takes action based on information it has received up to now, which the agent models in the form of a “state-space.”
State-space is a mathematical abstraction of the problem. It comprises of initial state, actions, transition model (the rules that specify what happens when action are taken), and goal test to show whether a problem has been solved.
So why is it that LLMs also seem to struggle with simple and basic logic puzzles?
LLMs are trained to predict the next word given an arbitrary set of previous words, and they learn these predictions based on statistical properties of human language. As they have no physical or spatial understanding of the world. So instead they end up pattern-matching rather than actual logical deduction, which leads to silly errors or hallucinations.
What is Alpha-Beta Pruning?
This is the same Alpha-Beta pruning they use in competitive game-playing AI (Chess). It trims branches of a decision tree that are certain to be worse than options the algorithm has already evaluated (pruning), which saves a ton of processing power and speeds up search algorithms.